Overview
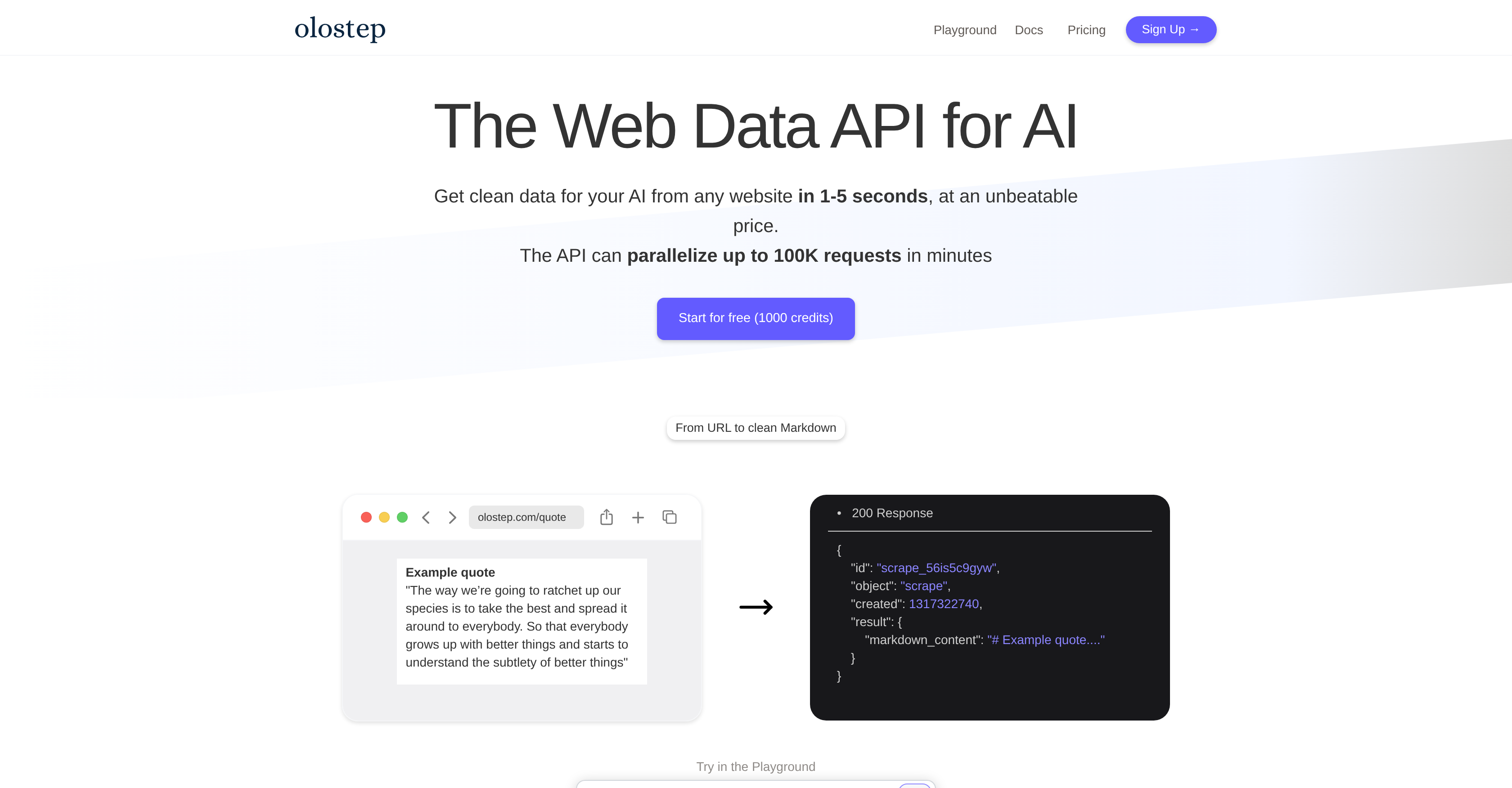
- Get AI-ready data in your preferred format without manual cleaning using clean Markdown transformation that removes unnecessary tags and clutter
- Extract structured data from popular websites instantly using pre-built parsers for Brave, Reddit, Instagram, Amazon, and Google Maps
- Process up to 100,000 URLs in minutes through concurrent batch processing that handles massive data volumes efficiently
- Build custom data extraction pipelines for any website using customizable parsers that adapt to unique project requirements
- Bypass bot detection reliably with premium residential IP addresses and built-in fallback mechanisms for consistent data access
- Scale scraping operations cost-effectively with parallel request handling that eliminates the need for additional scraping resources
Pros & Cons
Pros
- Cost-effective Web Scraping API
- Quick efficient data acquisition
- Developer-centric API
- Supports concurrent requests
- Customizable Parsers
- Supports Python and Node.js
- Clean data transformation
- High volume batch processing
- Ready-made Parsers for popular sites
- Transforms data to Markdown format
- Community channels
- Handles specific URL scraping
- Website subpage crawling
- Scrapes Brave searches data
- Scrapes Reddit data
- Scrapes Instagram data
- Scrapes Amazon product data
- Scrapes Google Maps data
- Supports adaptation
- Affordable pricing
- Reliable service
- Fast data extraction
- Handles pdf parsing
- Multi-depth crawling
- Premium proxies usage
- Rotating proxies
- Solving CAPTCHAs capability
- JS executed requests
- Crawls without sitemap
- Batched executions
- Extracts structured JSON data
- Capable of JS rendering
- Copes with rate limits
- Fast scraping scale
- Offers custom discounts
- Can parse docx content
- Offers refunds policy
- Data enriched output
- Data markdown format results
- Return id for future retrievals
- Possible retry for failed requests
- Includes interactive actions before extraction
- Option for HTML result format
- Concurrent batch thread executions
- Supports multi-depth website crawling
- Offers free API testing keys
- Has fallback systems for failures
- Credits packs for extra flexibility
- Transparent Practices
- Pro-rated plan switch policy
Cons
- Invite code required
- Limited programming language support
- Markdown output only
- Limited website compatibility
- No mobile compatibility
- Fixed endpoint structure
- Pre-built Parsers limitation
- No real-time scraping
- No on-premises version
- Access via API only
Reviews
Rate this tool
Loading reviews...
❓ Frequently Asked Questions
Olostep is a highly efficient Web Scraping API designed to gather and process data from various websites in a swift manner. It enables the extraction of clean data which is crucial for the development of AI technologies. With its developer-centric API, users have the capability to perform different operations including scraping specific URLs, crawling all subpages on a particular website, and processing large batches of URLs concurrently. To cater to unique project needs and promote adaptability, Olostep provides pre-built Parsers for structuring data from popular platforms and also allows users to create their own Parsers. The tool supports Python and Node.js and maintains a stringent focus on data quality by transforming extracted data into a clean Markdown format.
Olostep is cost-effective for web scraping due to its ability to perform concurrent requests and process high-volume data, reducing the need for additional scraping resources. Olostep supports efficient operations by catering to specific URL scraping, entire website crawling, and batch processing of up to 100,000 URLs. Moreover, it provides pre-configured Parsers for popular websites like Brave, Reddit, and Instagram, among others, eliminating the need for users to code these complex extractors from scratch.
To scrape data from a specific URL using Olostep, users employ the '/scrapes' endpoint of its developer-centric API. Using Python or Node.js, a request code can be written where the 'url_to_scrape' is specified. The request is sent to Olostep API for processing, and the clean, structured data from that URL is returned as a response.
To crawl all the subpages on a website using Olostep, users interact with the '/crawls' endpoint of the provided API. In the request code, users are required to specify the 'start_url' (the main website URL). They can also set 'max_pages', dictating the maximum number of pages intended for the crawl. This process can efficiently scrape all the subpages related to that particular website, thereby providing a thorough data extraction.
The Parsers provided by Olostep are unique as they are readily available for creating structured data from a variety of popular websites, making data extraction from these sources significantly easier. Prebuilt Parsers are available for platforms like Brave search results, Reddit, Instagram, Amazon, and Google Maps. Also, in order to cater to unique extraction requirements, Olostep allows users to build their own Parsers.
Olostep manages high-volume data scraping via its 'batches' service, where users can process up to 100,000 URLs concurrently. By sending a POST request to the '/batches' endpoint of the API with a list of URLs included under 'items', Olostep can execute mass data extraction within minutes, making it a highly efficient tool for large-scale scraping tasks.
Olostep supports Python and Node.js by providing its API functionality and scraping service compatible with these languages. Users can import necessary libraries and write request codes in Python or Node.js to interact with the Olostep's endpoints. This flexibility lets developers use their preferred programming language when working with Olostep's Web Scraping API.
Olostep ensures the quality of extracted data by transforming it into a clean Markdown format. This standard text formatting syntax is well-regarded for its readability and ease of use, helping users consume and process the scraped data more efficiently. It aids in removing unnecessary tags, characters, or clutter, ensuring that the final output is clean, structured, and ready for further analysis or usage.
Olostep provides data from popular websites such as Amazon, Reddit and Instagram through specially designed Parsers. When used, these Parsers enable extraction of varied data such as search results, suggested queries, user posts, comments, upvotes, user info from reddit; user details, follower counts, post metrics from Instagram; and product details, pricing, specifications, reviews from Amazon listings. This makes Olostep a versatile tool when working with different websites.
The Markdown format in Olostep functions as a tool for presenting the scraped data in a clean and readable form. The use of markdown syntax is prominent in removing any intact HTML tags, additional characters or elements, ensuring the high quality and structure of the final scraped data. This streamlined Markdown data assists in the hassle-free processing or analysis of the collected information.
Olostep is built to be reliable and efficient for web scraping. It is capable of fulfilling numerous requests concurrently, supporting high-volume scraping operations effectively. In addition, Olostep's built-in fallback mechanisms and premium residential IP addresses help evade bot detection, further enhancing the reliability of the service. Olostep can perform parallel operations processing up to 100,000 requests swiftly, making it extremely efficient for large scale data retrieval.
The procedure of customizing scraping in Olostep involves creating your own parser. Users can write unique Parsers to gather structured data based on their project-specific needs for websites not already covered by the pre-built parsers. This feature enhances the flexibility of Olostep by allowing customization in data extraction according to user requirements.
Yes, Olostep provides a distinct Parser meant for scraping data from Google Maps. By using the '@olostep/gmaps-place' parser, users can extract business information, reviews, and location details from Google Maps, making it very beneficial for location-based data aggregation.
The languages and tools that can be used to interact with Olostep include Python and Node.js. User interaction with Olostep occurs via its developer-friendly API, which includes different endpoints for conducting various service tiers such as scraping data from a URL, crawling all subpages on a website, or processing batches of URLs.
Yes, Olostep does provide a free usage tier. Using this free tier, users can obtain API keys and gain access to 1000 scrapes. However, users are required to get an invitation code to sign up and use this service. The get started for free option is clearly indicated in their pricing plan, making Olostep accessible for preliminary usage and evaluation.
Yes, Olostep can handle concurrent request operations. The API has the capacity to parallelize numerous requests, facilitating simultaneous data scraping actions. Whether it's scraping a specific URL, crawling all subpages of a website, or batch processing for up to 100,000 URLs, Olostep enables efficient concurrent operations resulting in rapid data extraction.
Olostep is an optimal choice for website data extraction in scenarios where users need clean, processed, and structured data quickly from multiple websites. It is particularly useful for AI development projects, as the created parsers ensure clean, structured data. Due to its large-scale batch processing abilities, Olostep is ideal for situations requiring extensive data extraction. The tool's customization abilities also make it versatile in handling unique project requirements.
Olostep is highly efficient in large-scale data scraping operations, capable of processing up to 100,000 URLs in a single batch. Users need to make a POST request to the '/batches' endpoint of the API, providing a list of URLs to be scraped. Olostep takes up this task concurrently, enabling the scraping of the high volume of websites within just 5-7 minutes.
To create a unique Parser in Olostep, users can utilize the customizable feature of the Olostep's API. Although the specifics on how to build this are not available on their website, it's likely a matter of defining unique parameters and settings that relate to the structure of the particular webpage you are looking to scrape, thereby personalizing how the data is extracted and structured from that site.
Pricing
Pricing model
Free Trial
Paid options from
$9/month
Billing frequency
Monthly
Refund policy
If users are not satisfied they can ask a refund at any time
Related Videos
Olostep Hackathon
Jason Chen•61 views•Aug 18, 2024