Nebius Token Factoryv1.1
Overview
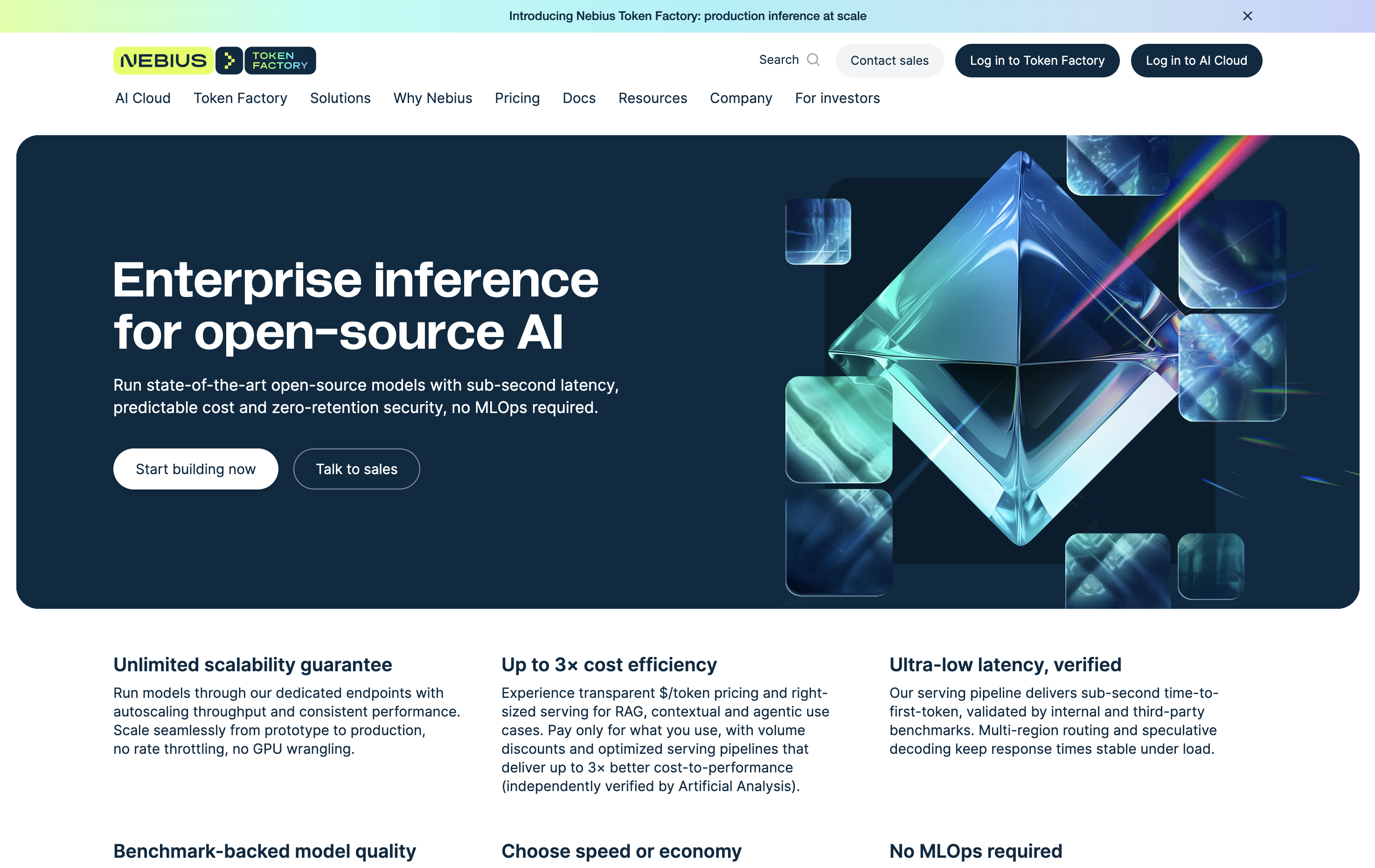
- Launch production AI applications instantly without GPU management or complex MLOps setup through fully managed infrastructure
- Scale to unlimited throughput with guaranteed 99.9% uptime and autoscaling performance for large-scale background inference
- Achieve sub-second response times verified by third-party benchmarks, delivering up to 4.5× faster performance than competitors
- Control costs with transparent $/token pricing and volume discounts, achieving up to 3× cost efficiency without throttling
- Deploy custom fine-tuned models on dedicated endpoints optimized for RAG systems and agentic workflows
- Ensure enterprise-grade security with zero data retention, secure routing, and SOC 2 Type II, HIPAA, ISO 27001 compliance
- Access 60+ validated open-source models including DeepSeek R1 and Qwen3 with multilingual consistency and reasoning accuracy
Pros & Cons
Pros
- Sub-second inference across open models
- No MLOps or GPU management required
- Transparent, usage-based $/token pricing
- Enterprise-grade SLAs and compliance
- Dedicated, autoscaling endpoints
- Multi-region routing for global performance
- Open-source ecosystem compatibility
- Benchmark-verified speed and efficiency
- Seamless prototype-to-production scaling
- Zero data retention for full privacy
- Integration with RAG and agentic workflows
- Free tier with 60 models
Cons
- Limited to supported open-source model families
- Requires API familiarity for integration
- Custom fine-tuning setup may need support involvement
- Performance tier selection affects cost
Reviews
Rate this tool
Loading reviews...
❓ Frequently Asked Questions
It’s an inference platform enabling organizations to run open-source AI models at scale with sub-second latency, predictable costs, and enterprise-grade security.
Leading open-source models such as DeepSeek R1, Qwen3, GLM-4.5, Hermes-4-405B, Kimi-K2-Instruct, OpenAI GPT-OSS 120B, and more.
Nebius uses transparent, usage-based $/token pricing. Costs vary by model and tier (Fast or Base), with volume discounts available.
Guaranteed 99.9% uptime SLA, autoscaling throughput, and sub-second time-to-first-token latency verified by third-party benchmarks.
No. Nebius provides fully managed infrastructure with dedicated endpoints optimized for production performance.
Yes. Custom fine-tuned models can be deployed on dedicated Nebius endpoints.
Yes. Token Factory ensures zero data retention, secure routing, and compliance with major enterprise standards (SOC 2 Type II, HIPAA, ISO 27001).
RAG pipelines, agentic inference, contextual applications, large-scale analytics, and enterprise-grade production workloads.
Sign up for free, access credits for 60+ open models via the Playground or API, and scale seamlessly as needed.
Predictable performance, no throttling, up to 3× cost efficiency, and top-tier benchmarked speed (up to 4.5× faster than competitors).
Pricing
Pricing model
Free Trial
Paid options from
$0.01/unit
Billing frequency
Pay-as-you-go