DiffRhythm
Overview
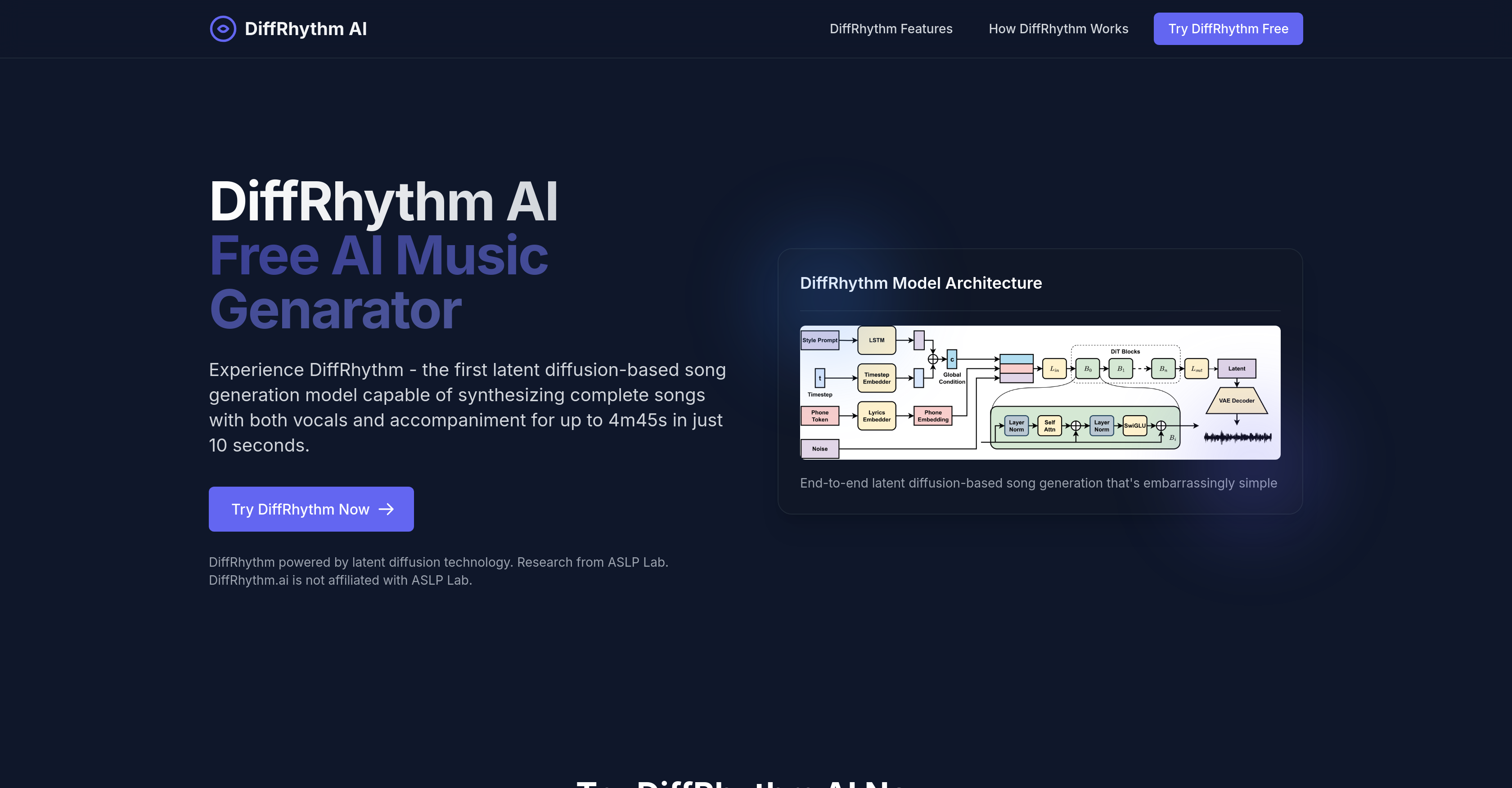
- Transform lyrics into complete songs with both vocals and music in under 10 seconds using latent diffusion technology
- Generate professional-quality audio with high musicality and intelligibility across any genre from a simple text prompt
- Create full-length songs up to 4 minutes 45 seconds with consistent audio quality throughout extended sequences
- Control musical style effortlessly by specifying genres like rock, pop, jazz, or classical in your style prompt
- Access commercial-ready music generation with business licensing for professional projects and content creation
Pros & Cons
Pros
- Generates complete songs
- Rapid song generation
- Requires minimal user input
- Capable of various genres
- Music style controlled by prompts
- Produces intelligible, high-musicality songs
- Scalable architecture
- Continuous capability enhancement
- Generates vocals and accompaniment
- Trainable on larger datasets
- Generates song in 10 seconds
- No need for multi-stage architectures
- Simple model structure
- Style control through text prompts
- Step-wise generation process
- Non-autoregressive for fast generation
- Advances over previous architectures
- High-quality music generation
- Consistency in extended sequences
- Efficiency in compressed latent space
- Match lyrics to vocals and accompaniment
- Allows commercial usage
Cons
- No melody input option
- Only text-based style control
- May infringe on protected styles
- Requires verification of originality
- Rapid generation may limit customization
- Dependent on lyrical clarity
- Complexity not adjustable
- Inconsistency in genre representation
- No user control on accompaniment
- Lyrics not auto-generated
Reviews
Rate this tool
Loading reviews...
❓ Frequently Asked Questions
DiffRhythm is able to generate a complete song in roughly 10 seconds.
DiffRhythm requires only two inputs to generate a song: the lyrics and a style prompt.
Absolutely, DiffRhythm can create songs across various music genres. Users have the option to specify their desired style in a prompt, guiding the song creation process.
Latent diffusion is a generative AI technique that works within a compressed latent space. It provides higher efficiency than standard diffusion models.
DiffRhythm uses latent diffusion technology to generate high-quality music quickly and efficiently. This technology allows for fast generation of complex audio while preserving coherence across extended sequences.
DiffRhythm produces audio of high musicality and intelligibility. Its advanced AI technology is capable of creating professional-sounding music.
Indeed, one of DiffRhythm's strengths is its ability to maintain consistency across extended sequences, a crucial aspect for creating full-length songs.
The style prompt in DiffRhythm serves as a guide for controlling the musical style. Users can dictate the genre or style of the song they want to create, from rock to pop, classical to jazz, and more.
DiffRhythm boasts a scalable architecture. With this feature, it can accommodate increased data to broaden its capabilities.
Yes, DiffRhythm is designed to be trained on larger datasets. This enables continuous improvement and expansion of its capabilities.
In DiffRhythm, user input is fundamental to the song generation process. Users provide the lyrics and the style prompt, which guides the AI in creating a song matching the provided specifications.
Yes, thanks to its scalable architecture, DiffRhythm promotes continuous enhancement and expansion of its capabilities.
By leveraging latent diffusion technology, DiffRhythm overcomes the limitations of traditional music generation models. It can generate high-quality, coherent audio much faster while maintaining consistency across extended sequences.
The maximum length of a song that DiffRhythm can generate is up to 4 minutes 45 seconds.
Yes, DiffRhythm generates complete songs, synthesizing both vocals and accompaniment.
Yes, only lyrics and a style prompt are required for DiffRhythm to generate a song.
DiffRhythm can cater to a broad range of genres guided by the user's text prompt. These can range from pop, rock, ballads, and jazz to many others.
The structure of DiffRhythm's AI model is designed to be straightforward and simple for users. It requires only lyrics and a style prompt for song generation, eliminating the need for complex data preparation.
Unlike conventional models that require complex multi-stage architectures, DiffRhythm uses advanced latent diffusion technology within an end-to-end structure to generate complete songs. This simple yet powerful approach makes it unique from other music generators.
Yes, DiffRhythm does offer a business plan intended for commercial use, which includes the appropriate licensing. However, users should still verify the originality of the generated music, disclose AI involvement, and ensure non-infringement of protected musical styles or content.
Pricing
Pricing model
Freemium
Paid options from
$6.99/month
Billing frequency
Monthly
Refund policy
Users can request a refund within 10 days of purchase if the product is unused or undownloaded.
Related Videos
STOP Paying for AI Music: Run YuE + DiffRhythm Locally & Own Everything!
The Oracle Guy: AI Unlocked•6.4K views•May 10, 2025