turbopuffer
Overview
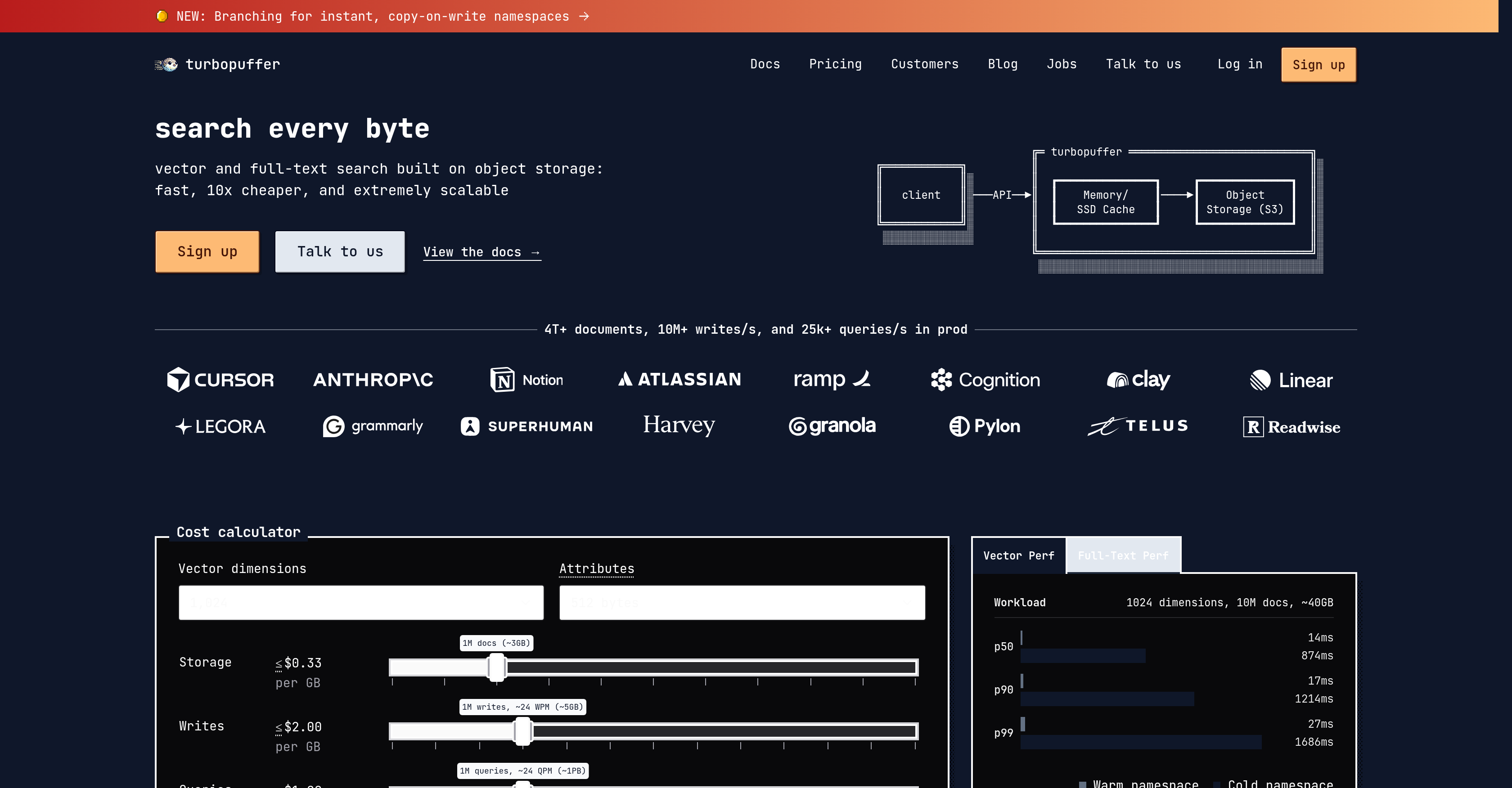
- Cut search infrastructure costs by 10x while maintaining equivalent or superior performance, thanks to object storage architecture that eliminates expensive traditional database overhead.
- Deliver sub-10ms median response times for real-time AI and semantic search applications, powered by low-latency vector and full-text search engine design.
- Scale effortlessly from prototype to production with automated scaling that handles 10 million+ writes per second and 25 thousand+ queries per second globally.
- Support massive datasets of 4 trillion+ documents and billions of vectors without performance degradation, enabled by object storage-based architecture that scales linearly.
- Achieve 90-100% recall@10 accuracy in vector search for reliable similarity matching in recommendation systems, using high-precision vector indexing.
- Refine search results instantly with metadata filtering to narrow down billions of vectors by specific attributes, providing precise control over query outputs.
- Combine full-text and vector search in hybrid queries for comprehensive, accurate results in AI applications, leveraging dual search capabilities within a single database.
- Experiment and iterate faster with instant namespace branching, creating isolated search environments for testing without affecting production data.
- Trusted by leading AI companies including Anthropic, Notion, and Grammarly for production workloads, validated through enterprise-grade reliability and performance.
Pros & Cons
Pros
- 10x cheaper vector search
- Faster search capabilities
- Automated scaling
- Low latency responses
- Supports billions of vectors
- Hybrid search capabilities
- Metadata filtering
- Instant namespace branching
- Scalable database
- Object storage based
- High-performance similarity search
- Cost-effective
- Handles massive data
- 4T+ document handling
- 10M+ writes/s
- 25k+ queries/s
- Sub-10ms p50 latency
- Full-text search capabilities
- Universal API
- Good documentation
- Trusted by leading companies
- Simple integration
- High recall rates
- Unlimited scalability
- Customizable
- Low complexity
- Order of magnitude cost savings
- Easy to use
- Flexible architecture
- Fast performance
- Reliable
- Secure
- Compliance features
- Namespace metadata
- Authentication support
Cons
- Performance varies
- Data handling ambiguity
- Lack of SSL encryption
- Cost savings unclear
- Limited pinned namespaces
- Vague production limits
- Query restrictions per namespace
- Exact capabilities unconfirmed
- Specific latency unclear
- Queried document limitation
Reviews
Rate this tool
Loading reviews...
❓ Frequently Asked Questions
The main application of Turbopuffer is primarily in areas such as artificial intelligence, semantic search, recommendation systems, and other use cases that require high-performance similarity search.
Compared to traditional vector databases, Turbopuffer offers faster search capabilities with lower latency in responses. It's significantly cheaper and can support billions of vectors, exemplifying greater performance both in terms of speed and cost.
Key features of Turbopuffer include automated scaling, low latency (sub-10ms p50), the ability to support billions of vectors, full-text search capabilities, hybrid search, metadata filtering, and significant cost savings compared to traditional vector databases. Another unique feature is 'namespace branching', which enhances flexibility and performance.
Turbopuffer handles massive amounts of data, having the capacity to deal with 4 trillion+ documents, 10 million+ writes per second, and 25 thousand+ queries per second in production systems. This showcases its ability to manage big data and process exceedingly high volumes of information.
Turbopuffer supports both full-text and vector search. It also enables hybrid search, which is a combination of full-text and vector search, providing comprehensive results.
Turbopuffer is effectively used in fields that require high-performance similarity search. This includes, AI applications, semantic search, and recommendation systems.
I am unable to provide specific details on how automated scaling works in Turbopuffer based on the information on their website. However, this feature likely enables Turbopuffer to dynamically adjust to changes in workload ensuring optimal performance.
Namespace branching in Turbopuffer is a unique feature that likely enhances both its flexibility and performance. The exact details of how 'namespace branching' is implemented or functions is not explicitly divulged on their website.
Turbopuffer's latency for responses is remarkably low, with a median duration (p50) of under 10 milliseconds. This contributes to a fast and smooth user experience.
Turbopuffer is cost-effective due to its fundamental design around object storage, which is cheaper compared to alternatives. It's cited to be 10 times cheaper than conventional vector databases whilst offering equivalent or superior performance metrics.
Turbopuffer handles similarity searches by providing high-performance functionality. It executes these searches quickly, efficiently, and scales smoothly due to its software architecture designed around object storage.
Turbopuffer is employed by a number of leading companies. These include Cursor, Anthropic, Notion, Atlassian, Ramp, Cognition, Clay, Legora, Linear, Grammarly, Superhuman, Harvey, Granola, Pylon, Telus, and Readwise, among others.
While specific figures are not available, Turbopuffer's vector search provides very high accuracy with a recall@10 rate between 90 and 100 percent. This means in most cases, the true nearest neighbour is within the top 10 results.
Metadata filtering in Turbopuffer is likely a technique used to refine and narrow down search results based on the metadata associated with documents and vectors. The exact details of how this process is implemented are not disclosed on their website.
Turbopuffer can handle over 25 thousand queries per second on a global level according to data from production systems. However, for the specific limit within a namespace it's 1 thousand queries per second.
Turbopuffer has the ability to support billions of vectors due to its scalable design centered around object storage. This provides a robust framework for managing and processing an extraordinary amount of vectors efficiently.
Hybrid search in Turbopuffer combines the power of both full-text and vector search. This yields a more comprehensive and detailed search output than either method would individually, offering a broader and more accurate set of results.
The significance of object storage in Turbopuffer lies in its ability to provide faster, more efficient search capabilities, and extreme scalability. It is key to the cost-effectiveness of the database, making it 10 times cheaper compared to traditional vector databases.
The maximum number of documents Turbopuffer can handle globally is over 4 trillion documents. There's no disclosed limit for the maximum number of documents it can manage.
The specific dimensions possible with Turbopuffer's vector search are not explicitly stated on their website. However, given its application within AI and semantic search, it can presumably handle high-dimensional vector data.
Pricing
Pricing model
Paid
Paid options from
$64/month
Billing frequency
Monthly